
controlpro
[논문 리뷰] Breaking a Fifth-Order Masked Implementation of CRYSTALS-Kyber by Copy-Paste 본문
[논문 리뷰] Breaking a Fifth-Order Masked Implementation of CRYSTALS-Kyber by Copy-Paste
controlpro 2023. 3. 2. 17:52앞으로 논문 관련해서 하나씩 계속 리딩하면서, 읽을 예정 특히 PQC 쪽은 부채널 쪽에서 굉장히 핫한 이슈이고, 이를 부채널 분석하는 것만으로도, 좋은 논문 거리가 되기 때문에 계속 follow up 해야할듯 하다.
Log
2023-03-06 제작 완
0. Introduction
양자 컴퓨터가 개발된다면 Shor's algorithm에 의해서, 지금까지 개발된 RSA의 기반 문제가 계산이 되어버리는 한계점을 가지고 있기 때문에, 현 양자 암호의 개발이 시급한 상황이고, NIST에서 2017년부터 공모를 시작해서 지금은 Round 4가 진행되고 있고 Kyber는 현재 Round 4까지 진행된 상태이다.
부채널 분석의 큰 변화라고 하면 크게 두 번이 있다. 한 번은 처음 부채널 분석이라는 것을 제시했던 Kocher의 차분 계산 분석이 하나이고 나머지 하나는 2017년 부터 본격적으로 연구가 되어진 딥러닝 기반 부채널 분석이 있다. 특히 딥러닝 기반 부채널 분석은 기존의 암호의 부채널 분석을 막는 masking, shuffling 등 다양한 countermeasure를 따로 계산할 필요 없이 딥러닝 하나만으로 기존의 암호를 공격하는 모습을 보이는 경우가 많다. 이 논문은 회귀 모델을 사용해서 CRYSTALS-KYBER를 공격한 논문 중의 하나이고, 커뮤에서는 굉장히 핫한.... 논문이다.
0.0 contributions
1. CRYSTALS-Kyber에 대한 5차 마스킹에 대한 분석을 진행
2. 회귀 모델를 사용한 w차 masking에 대한 공격을 실행할 수 있음
> 간단히 읽어보면 w-1 차 maksing을 학습하고 w차를 올려서 공격하는 방식으로 공격한다.
3. cyclic rotations이라는 message 복구 방법을 사용한다.
> 각 바이트의 첫 비트가 다른 것들보다 영향이 큰 듯 보인다. (카이버에서)
1. Previous work
이번 섹션은 전에 CRYSTALS-Kyber를 공격했던 다양한 기법에 대해서 알아보겠다. 사실 이번 논문은 격자기반 pqc에 대한 이해가 먼저기 때문에 해당 포스킹은 나중에 또 기회가 되면 진행을 해보겠다.
보통 현재 딥러닝 기반 부채널 분석이라고 하면 profiling 기반 부채널 분석이 대세이고 CRYSTALS-Kyber역시 해당 방법으로 공격이 많이 됐다.
2. Background


ring Rq CPAPKE는 ring Zq[X] /( X^256 + 1) 에서 뽑는다. 추후 KYber에 대한 포스팅이 있을 예정이다.

파형 수집하는 부분
해당 부분은 저자들이 부채널 파형을 수집한 것이다. 다항식의 계수를 마스킹하게 되어 있는데, 이때 계수에 마스킹을 씌운 부분이다. 해당 과정은 decapsulation부분의 re-encryption 과정에 있는 부분이다, 위의 CCAKEM.Decaps 확인
3. 공격
늘상의 profiling attack이 그렇듯이, 해당 공격도 두단계로 나뉘게 된다. 즉 profiling 단계와 attack 단계로 나뉘게 된다. 여기서 profiling 단계는 4차 마스킹 단계에서 Batch Normalization을 한 gamma parameter를 사용하여 5차 마스킹에 대한 gamma parameter를 학습을 시킨다. profiling 단계는 다음과 같다.

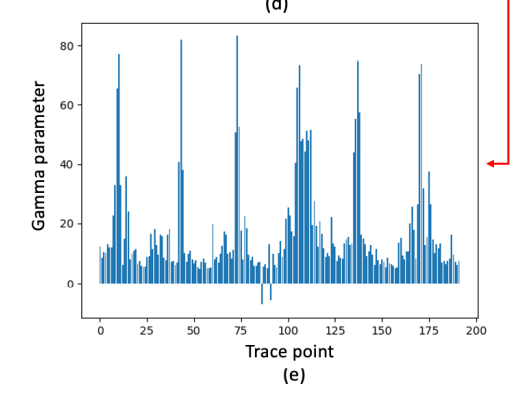
위의 그림은 4차 마스킹이 적용되어진 파형이고 해당 파형을 학습시킨 다면 batch normalization 부분의 gamma vector가 학습이 된다.

해당 값들 처럼 gamma parameter를 학습했다면, 이제 이를 5차 파형을 학습 시키기 위해서, 다음과 같이 반복되는 부분을 복사해서 확장한다.

그림을 보면 다음과 같이 하나의 peak가 늘어난 것을 확인할 수 있다. 해당 vector들을 기본으로 학습을 시키면 다음과 같은 gamma parameter가 나오게 된다.
3.1 Recursive learning method
중요한 아이디어는 아까도 언급했듯이 (w-1)차 마스킹이 학습된 M^(w-1)의 모델을 이용해서 w차 마스킹을 공격하는 것이다.
신경망 기반의 부채널 분석은 다음을 증명한 바가 있다.
1. LWE/LWR PKE/KEM 체계의 1차 마스킹된 소프트웨어 구현에서 두개의 메시지 공유 해당하는 세크먼트를 식별할 수 있다.
2. 공유된 xor 값을 통해서 진짜 label값을 얻을 수 있다.
그러나 해당 내용은 고차의 마스킹으로 갈수록 학습을 하기 위해서는 새로운 기법을 추가해야한다. (아마 4차까지 마스킹까지가 그냥 단순 학습으로만으로 가능한 부분일 듯). 여기서 말하는 새로운 기법은 위에서 계속 말했던 w-1차 마스킹에 학습에 사용한 vector들을 w차 마스킹에 학습하는 데 사용하는 방법이다. 여기서 중요한건 다른 Dense층이나 다른 weight들은 모두 random으로 초기화 한채 Batch Normalization에서의 gamma parameter만 복사를 한다는 것이다.
Batch Normalization으로 돌아가보자..

여기서 gamma와 beta parameter만이 training 과정에서 사용되는 벡터이다. (back propagation에서만 업데이터됨) 여기서 gamma parameter가 큰값을 가진다는 의미는 해당 부분이 높은 중요도가 있다는 것 확인할 수 있다.
본 논문에서는 w-1차 학습 모델 M^(w-1)에 대해서 input이 x = x1 || x2 || x3 || x4 ... || xw 와 같이 나란히 붙어서 있는 값이다.
w차 학습 모델 M^w에 대해서 input이 x = x1 || x2 || x3 || x4 || .. .x(w+1) 와 같다. 이때 세팅 되는 BatchNormalization은 다음과 같다.

간단하게 말하면 해당 것들은 그냥 다음 모델의 parameter로 한번더 사용된다는 것으로 확인할 수 있다.

위의 그림은 저자가 공격하는 부분인 1차 masked_poly_frommsg의 전체 파형이고, 아래는 첫번째 ,message bit를 label로 하여, 학습한 결과 이다. peak가 두번 보이는 것을 확인할 수 있다. 위의 masked_poly_frommsg를 확인해보면 poly가 2차원 배열로 선언되어 있는 것을 확인할 수 있는데, index 0과 1 부분을 확인한 것 같다. 이런 식으로 학습한다면 고차 마스킹(w > 4) 인경우도 학습할 수 있다는 것이다. (뭐 weight를 확장했으니까 전이학습이랑 다르다고는 하는데... 딥러닝 쪽은 너무 코에 걸면 코걸이 귀에 걸면 귀걸이 느낌이 강해..)
초기의 pqc에 관한 딥러닝 공격은 message 자체를 label로 사용하는 학습이 다수 있던 반면 random 마스킹을 추출할 생각을 하지 않고. (이말은 sbox 에 마스킹이 되어있지만 label로는 똑같은 중간값으로 학습한다는 것 같다.)
3.1 Input Selection
내가 모든 딥러닝 관련 논문을 읽으면, 중요하게 생각하는 것이(지도학습의 경우) 입력과 라벨이 무엇인지 확인하는 것이다.
위의 x = x1 || x2 || x3 || x4 || ... || xw 는 사실 좀 이해가 잘되지는 않았다. 저거를 그냥 피크를 주변으로 자르는 건지 아닌 건지 확인을 해야 한다.
수식을 쓰기는 좀 힘드니까 정의는 논문 대로 인용하면 다음과 같다.


사실 아직까지 x가 가지고 있는 의미를 크게는 잘 모르겠다.
간단히 정리하자면 Fig 4에 있는 파형 그림은 실제로 측정한 값이 아니라, Fig 5에 있는 것처럼 gamma parameter값들이 peak가 뜬 부분을 이정 부분 잘라서 사용한다는 붙여서 사용한다는 것이다. 이부분이 masking이랑 관련이 있다고 생각하고

그림과 같이 설명하면 , 1차 마스킹이 되어있는 전체 파형을 가지고 이런 gamma parameter를 측정을 하고, 해당 gamma parameter 에서 peak가 뜬 부분(여기서는 대충 100point 부분이랑 1600point 부분)의 파형을 가지고와서

빨간색으로 표시 되어있는 부분만 가지고 와서, 파형을 만들면

이런 파형이 된다는 것이다.(위 그림은 4차 마스킹에 대한 파형이므로 4+1개의 조각들이 나옴) 이런 파형을 input으로 하고 message bit를 label로 하는 모델이 만들어지는 것이다. (여기서는 message bit가 256bit라고 한다.)
4. Model 및 공격
학습하는 데 사용한 모델은 다음과 같다.

아마 이제 여기서 Batch Normalization 1 요 부분에서 gamma parameter가 측정이 될 것이다.
4.1 Cyclic rotation method
링기반 LWE/LWR의 메시지는 해당 암호문을 조작해서, 공격이 가능하다는 것을 보였다.
본 논문에서는 암호문의 마지막 6개의 비트를 앞으로 순환 시켜서 사용했다.

이런식으로 순환으로 비트를 조정한다음에 잘 추측을 하는 비트 번째를 이용할 예정이다.
5. Experimental results
해당 모델에서는 각각의 w차 마스킹 마다 30k의 학습 data set을 사용하였다. 공격자는 공개키를 통해서 ciphertext를 만들어 낼 수 잇고 이를 통해 분석이 가능하다. 여기서 의문인점은 논문 [27]에 나온 byte-wise cut-and-join을 사용해서 30k의 train set을 960k로 train set을 늘렸다. 따라서 논문 [27] (본 논문을 읽기 위해 사실 선행되어야 하는 논문이다)의 부분을 보면 다음과 같다.

그래서 여기서는 32배 크기의 for bytes를 사용해서 크기를 늘렸다는 것 같다. ([27]번 논문을 자세히 읽어봐야할 것 같다.)
이런식으로 각 bit마다 모델을 구성하면 총 8개의 모델을 학습시킬 수 있고, cyclic rotation을 적용하면 두개의 모델만으로 나머지를 복구할 수 있다.
결과는 다음과 같다.